Motivation
利用大量的单语语料提升 MT 效果。
前人工作有一些共通的原则:
- Initialization: 利用双语词典来 初始化 MT 系统
- Language modeling: 通过将 seq2seq 系统作为一个 denoising autoencoder 来利用强能力的 语言模型
- Back-translation: 通过 back-translation 将无监督任务转化为监督任务
Methods
这篇工作试图将上面的这些原则分别与 NMT 模型和 PBSMT (Phrase-Based SMT) 模型结合,并在无监督数据上进行尝试。
Unsupervised NMT
Initialization
- 直接将两种语言的单语语料拼接起来
在拼接的语料上做 BPE tokenization
在拼接的语料上对得到的 tokens 做 embedding,将该 embedding 作为初始化
这样做比根据双语词典来做初始化要简单,且若是相关语言,自然会有重合的 BPE tokens。
Language Modeling
在 NMT 中,通过学习一个 denoising autoencoder 来建模,学习目标为最小化下面的 loss
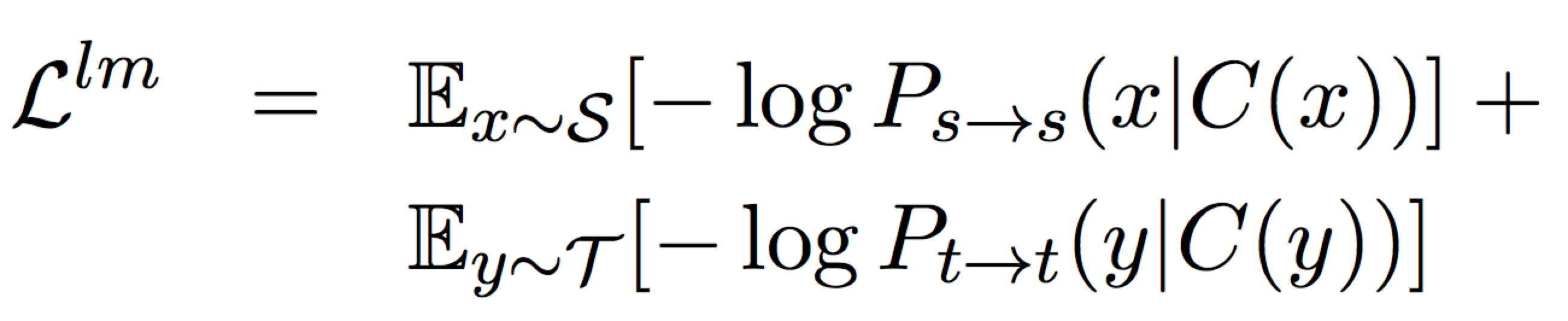
这里 C 是 noise model,会随机将一些词替换或删除。
Back-Translation
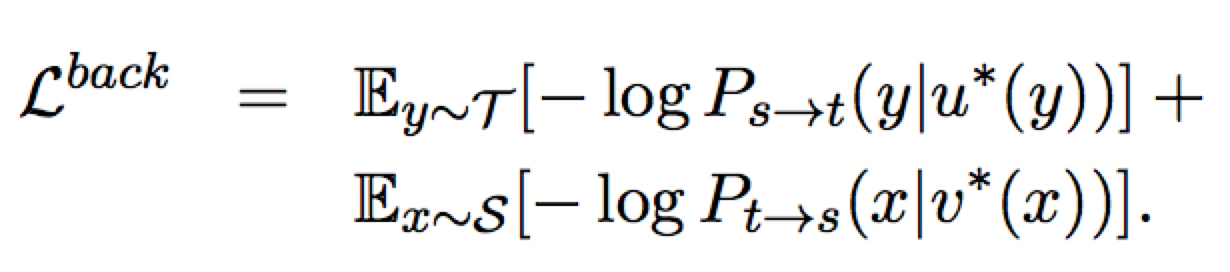
这里 $u^{\star}(y)$ 和 $v^{\star}(x)$ 是通过模型 infer 出来的最大概率的伪源语句子。
作者在这里强调在 BP 时不会对生成句子的部分模型进行 BP ,一方面是简单,一方面是没有观测到这样做可以带来性能提升。
模型的最终 loss 是
Sharing Latent Representations
通过共享参数来保证语言模型学到的表示能够很好的应用在翻译任务中。
没看懂:是两种语言的 encoder 和 decoder 的参数都共享吗?
Unsupervised PBSMT
PBSMT 系统的打分准则为
这里的 $P(x|y)$ 由 “phrase tables” 产生,$P(y)$ 由语言模型产生。
对双语语料,PBSMT 系统:
- 对齐 source 和 target 短语
- 产生 pharase tables ,每一项为一个 n-gram 短语 map 到另一种语言的 n-gram 短语的概率
对于无监督任务,最关键的是需要生成 pharase tables ,这需要用到之前提过的三个准则。
Initialization
这里以单个词来代替短语,短语表中每一项值的计算公式如下:
其中 $T$ 是调整分布”峰值程度”的超参( T = 30 ),W 为源端 embedding 到目标端 embedding 的映射矩阵,$e(x)$ 是 $x$ 的 embedding。
Language Modeling
使用 KenLM 来学习 n-gram 模型,当然也能使用 NN 来做。语言模型在后面的迭代中保持不变。
Iterative Back-Translation
使用无监督方法学到的短语表和目标端的语言模型来建立一个种子系统,之后通过同样的迭代方式来增强翻译效果。
Experiments
Setup
数据集
- English-French
- English-German
- English-Romanian
- English-Russian
English-Urdu
其中前两个语言对用于和前人工作进行比较;后三者属于 low-resource 或不相关的甚至基本字母都不同的语言,用来测试 PBSMT 效果。
初始化
- 使用 fastText 来生成 BPE embeddings (或 n-gram embeddings)
- 对 PBSMT ,分别使用两种语料训练 n-gram embeddings,然后使用 MUSE 库来对齐。
- 短语表包括 60 million phrase pairs = 300000 phrases x 200 其最相关 phrase
Training
略
Results
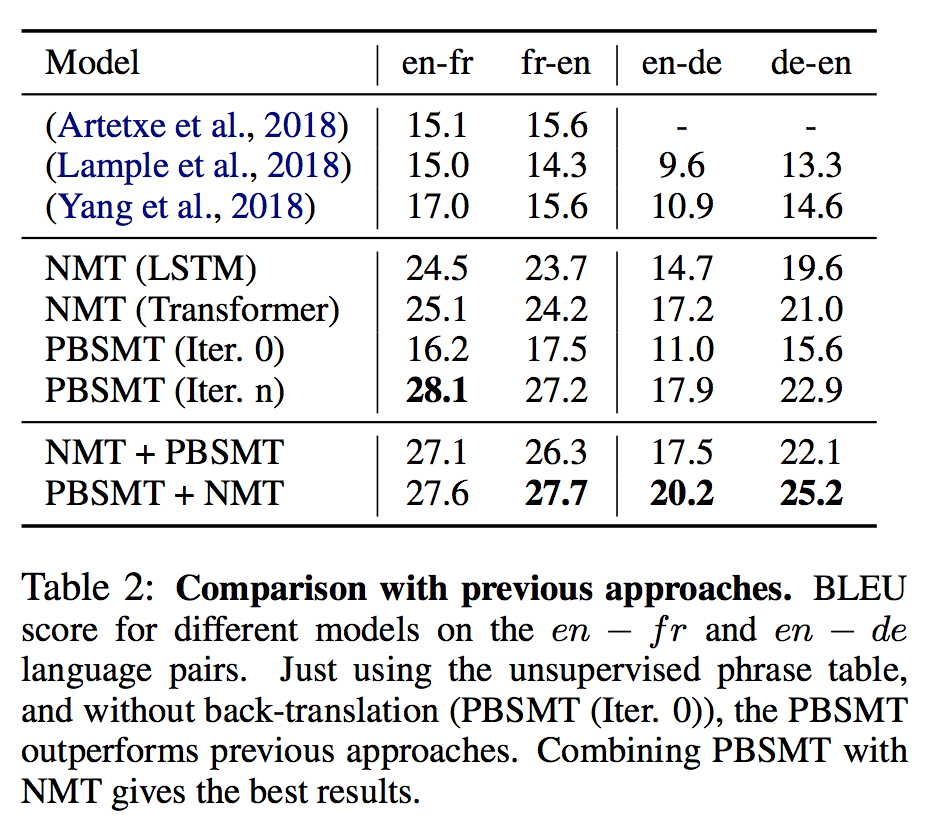
与前人工作比较 (英法/英德)
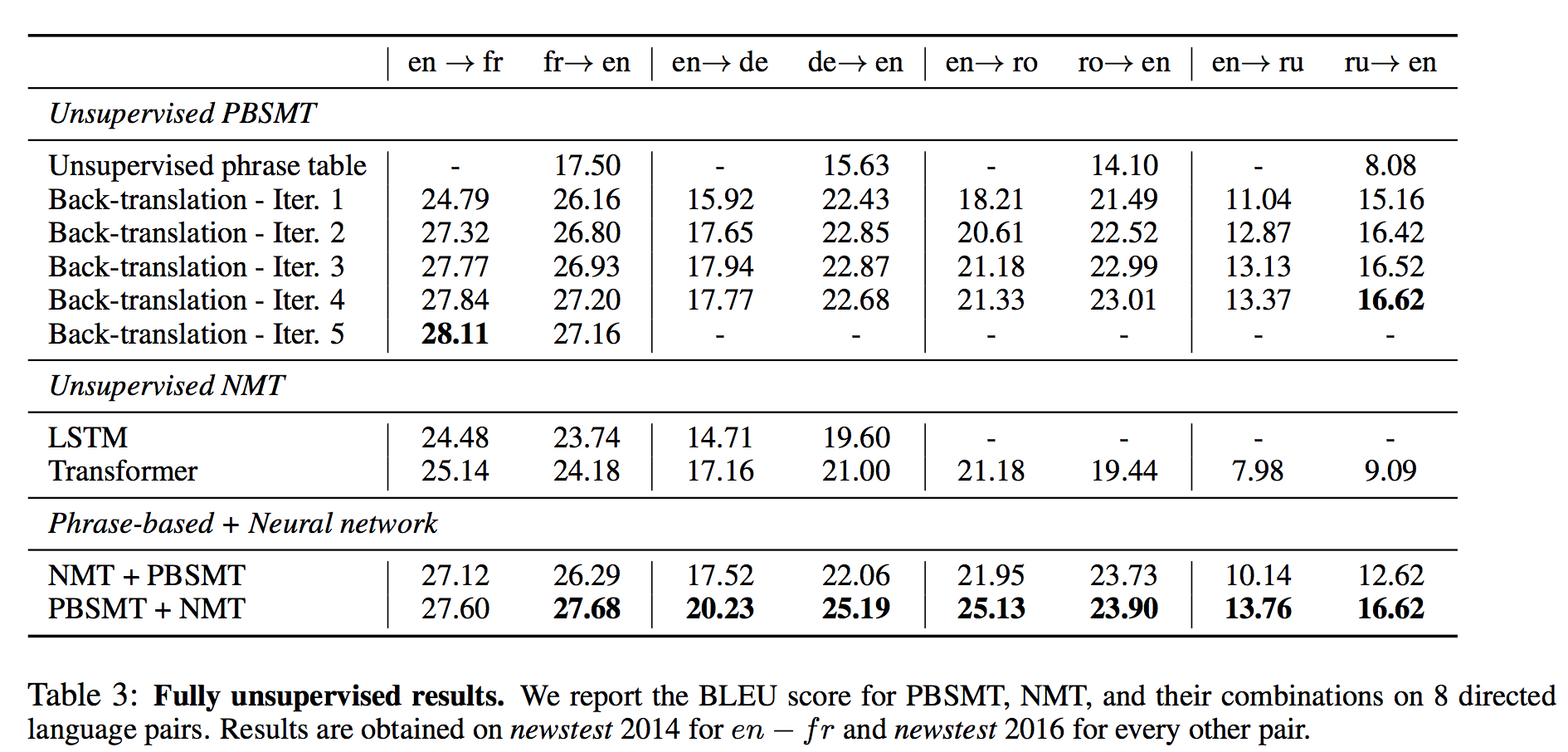
全部结果 (五种语言对)
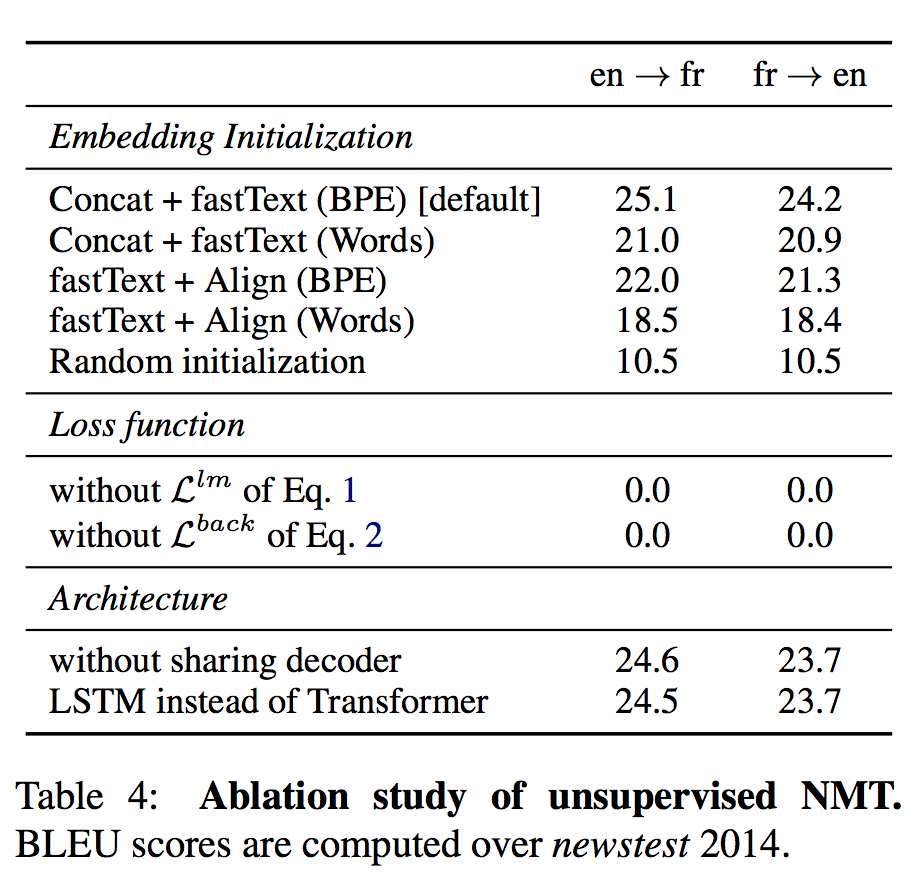
NMT Ablation Study
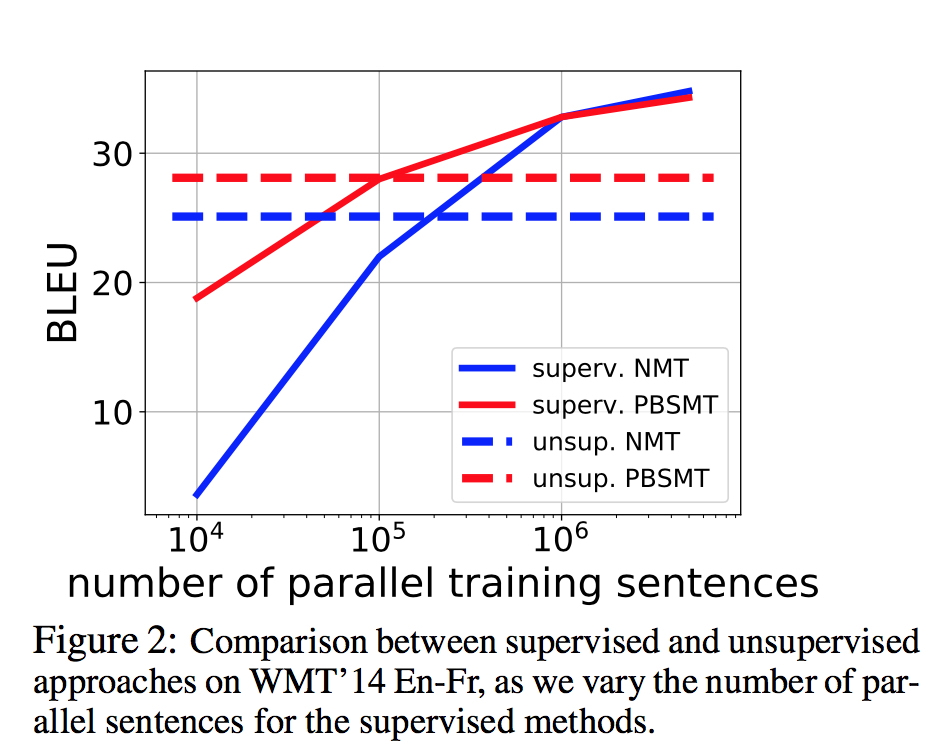
与有监督方法比较
PBSMT Ablation Study
从左到右分别观察了不同的参数对结果的影响:
- 初始化质量
- 语言模型训练语句数
- Back-translation 中生成的语句数
