Motivation
NMT方法倾向于 overfit 到常见词和短语,忽视那些少见的情况。【Zipf’s law (第n常见词出现频率为最常见词的 1/n)】而这些少见的词有时非常重要,比如领域相关的专有名词。
作者认为原因并不是表面上的词表大小限制或罕见词的 embedding 效果不好,而是神经网络结构本质决定的:高频句对和低频句对都会对共享的参数产生影响,而高频句对显然影响更大,低频句对甚至会被认为成噪音。
作者进一步分析 SMT ,认为其是离散的、符号化的系统,对特例效果更好。因此,直觉上来看,应该以擅长学习普适规则的 NMT 系统为基础,并以擅长记忆特例的 SMT 系统作为补充。后者在本文中以 memory 的形式加入到 NMT 中。
Methods
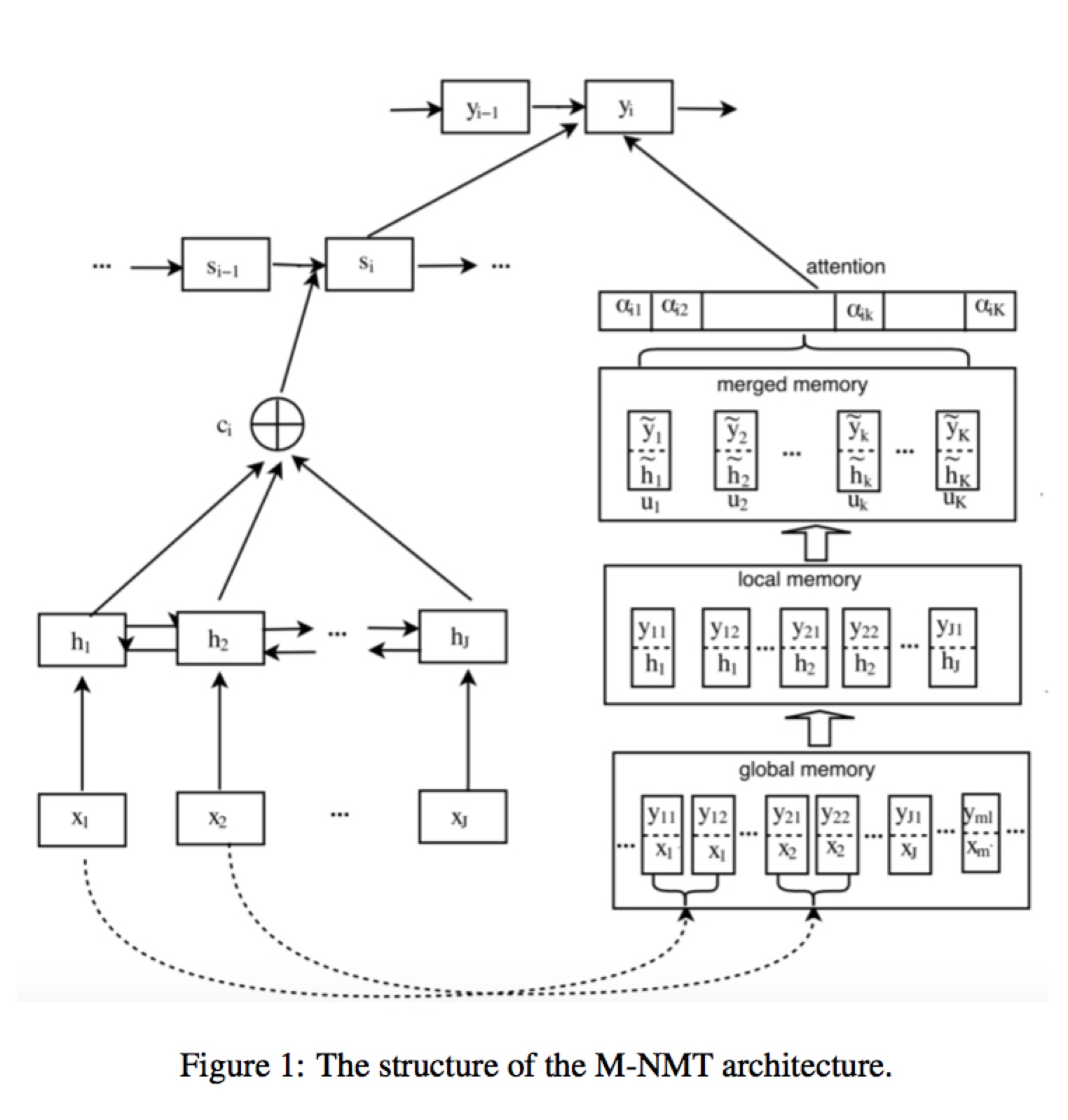
这里有三种不同的 memory element,分别是
- global memory
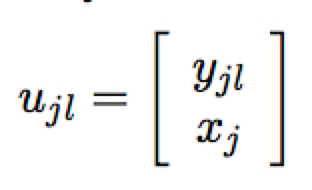
- local memory
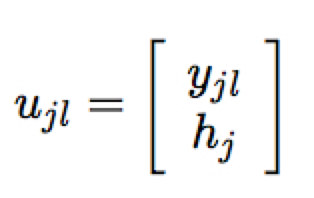
即将对应出现 $x_j$ 的 $h_j$ 作为 memory 的查询
- merged memory
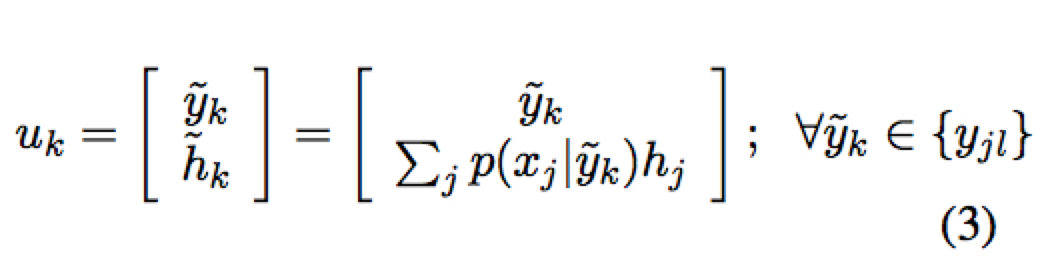
这里是将 local memory 中所有相同的 y 进行整合,将它们的 h 按照一定的概率分布取期望。这里的概率分布可以是人工设定的词典或是 SMT 系统的词典。
得到的 memory 使用 attention 机制作为后验整合到预测过程中,其中能量值的计算如下
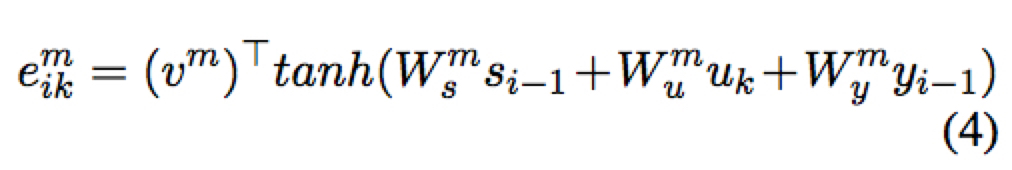
计算 attention
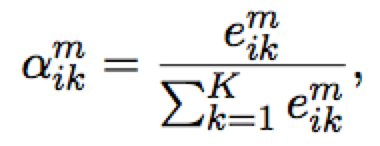
将得到的 attention 值与 NMT 模型得到的后验 $p(y_i)$ 作插值
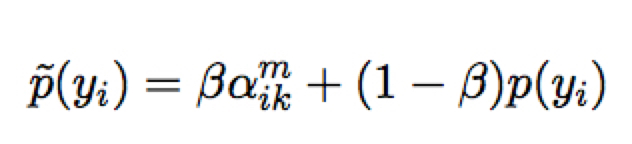
训练时,可以只训练 memory 模块的 attention 的参数,保持 NMT 模块的参数不变。这里考虑期望得到的 attention 应该是正确对应训练词对的位置为 1 的一个 one-hot 向量,计算其 cross entropy 作为训练目标,即如下实际目标
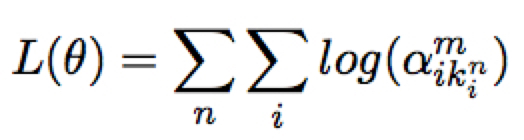
其他
文中对 SMT 系统具体如何整合到这一 memory 框架中以及如何处理 OOV 单词的问题也有具体的描述。