Motivation
NMT能够达到很好的翻译效果,本文旨在探索NMT模型学习语言词法学的能力.
本文主要想研究如下相关问题:
- NMT架构的哪一部分负责捕捉词结构(word structure)?
- 不同组件之间的分工如何?
- 不同的词表示(word representations)如何帮助更好的学习词法特征和model非常见词?
- 目标语言对学习词结构的影响?
Methods
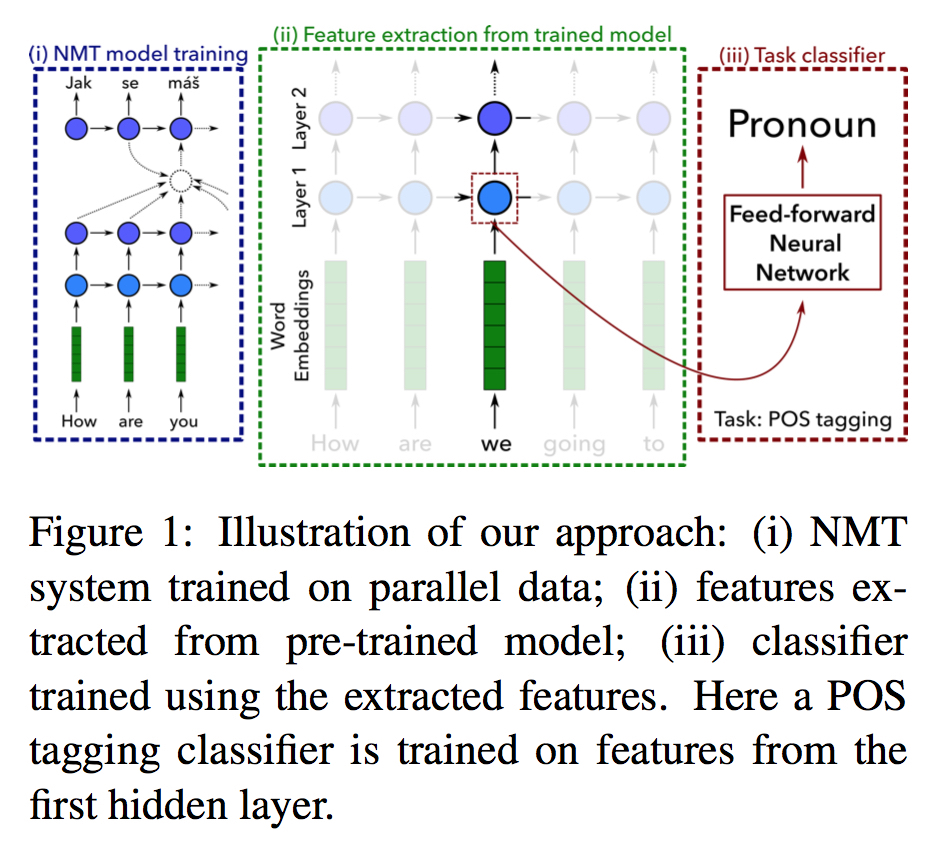
主要通过三步:
- 基于平行语料训练一个NMT系统
- 使用训练好的NMT系统(的不同部分)提取词特征表示
- 使用提取的特征训练一个其他任务的分类器C
通过对C的质量分析,可以间接获得MT系统提取特征的量化分析
Experiments
实验充分,结论主要有如下几个,对应Motivation中的几个问题
- Character-based representations能够更好的学习词法,尤其是对低频词效果而言。
- encoder底层注重词结构,深层提升翻译质量,似乎更注重词含义。
- 目标语言的不同会影响MT系统学到的信息。词法较少的语言作为目标语言时,源端词表示会更好。
- decoder几乎不关注词结构,这方面功能更多的由attention机制承担。