[TOC]
Motivation
当前的提升NMT效果的方法主要有:
- OOV词的翻译
- 设计attention机制
- 高效参数学习
- 利用源端语法树
作者发现长距离上的句法错误经常出现在翻译结果中,说明线性RNN不容易捕捉到细微的长距离word dependency。
这种长距离的词语相关可以通过句法依赖树来解决。好处有两点:
- 句法树可以作为翻译的语法标准验证
- 句法树可以作为context辅助后面的翻译
但是想法的实现有很多困难:
- 如何使用RNN建模语法结构树
- 如何使用同一网络同时进行目标词生成和语法结构建立
- 如何有效利用目标端句法context辅助目标词生成
本文主要采用的是 Jointly 产生 目标词 和 Action 的改进Decoder的方法
Methods
Dependency Tree Construction
算法: arc-standard algorithm
利用一个栈和一个buffer,定义三种transition actions

语法结构树和transition actions序列等价
对长度为n的句子,每个词需要入栈和出栈一次,则transition actions序列长度l=2n
Model
- 模型目标
总体上来说,模型定义为
其中 $a_{j} \in{\{SH, RR(d), LR(d)\}}$
只有在产生动作SH时,才预测下一个词,通过定义函数$\delta$来实现这一点
则
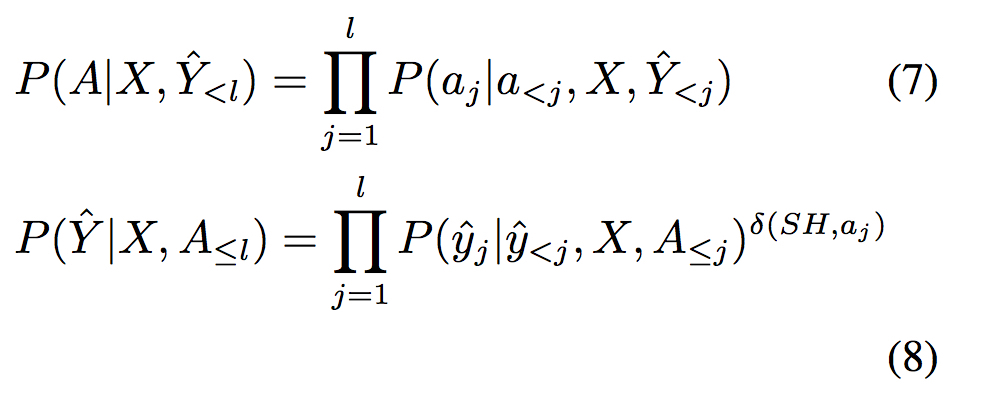
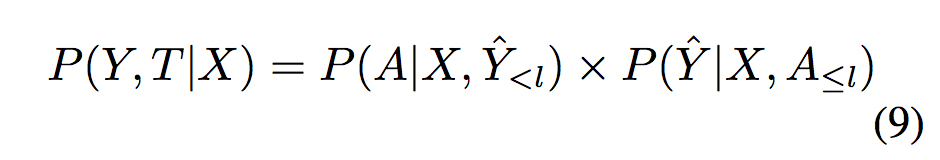
- 模型架构
利用两个相互关联的RNN来分别model Y和A,例如
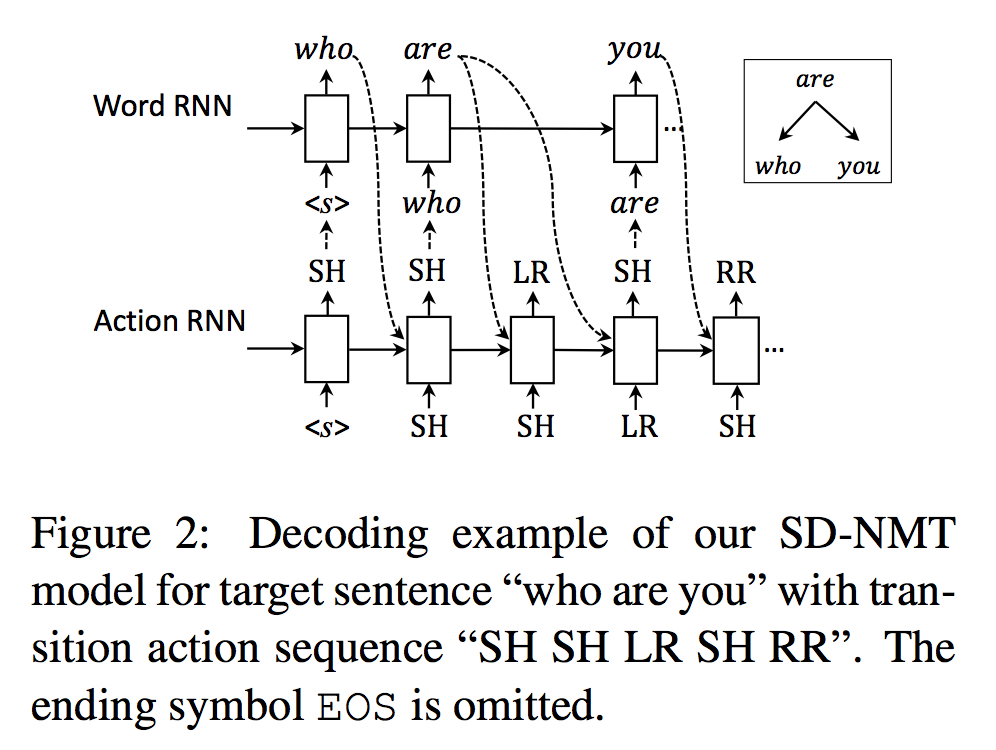
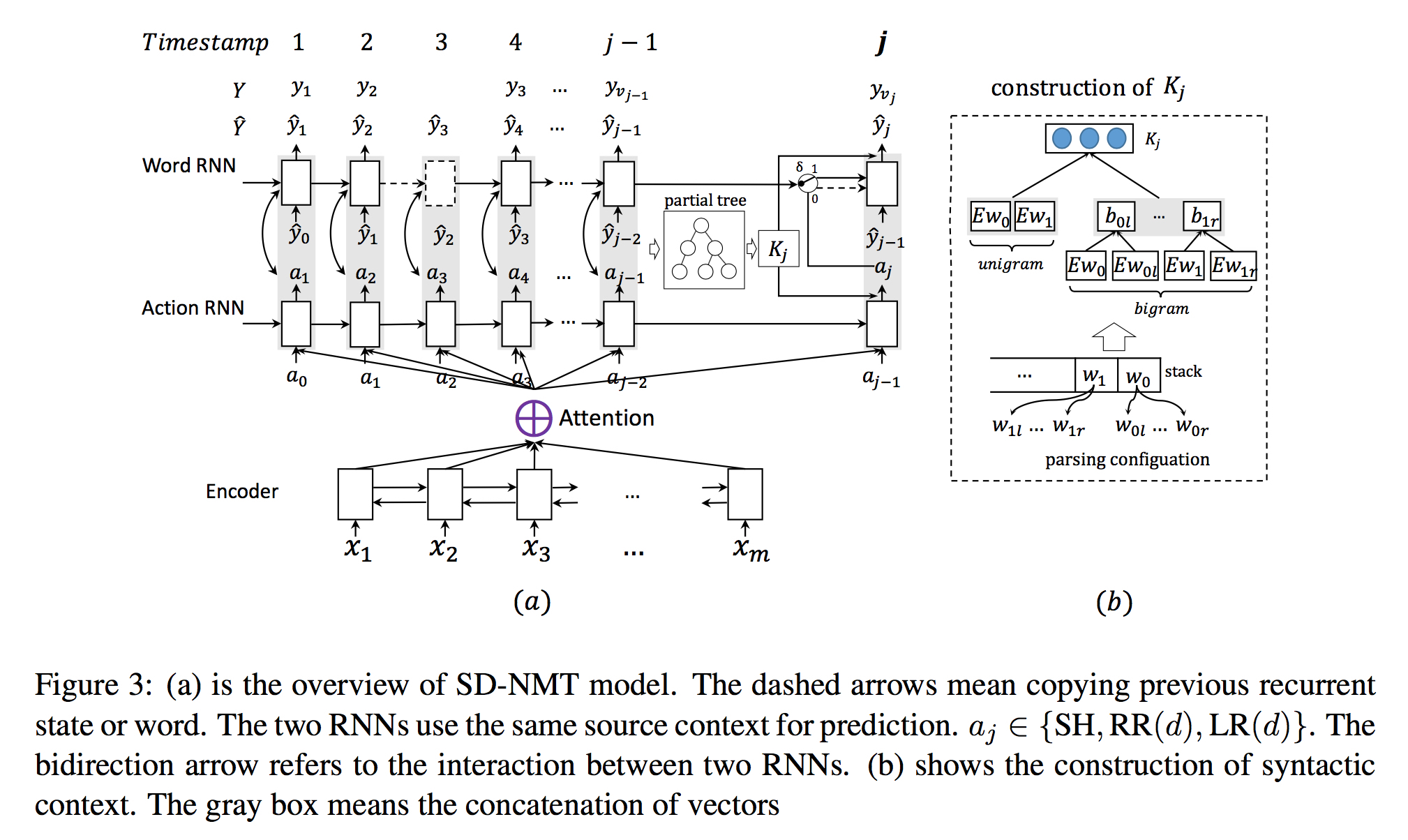
总体架构如下
- 终止条件
终止条件除了word-RNN产生EOS之外,还要求栈里的所有词都经过规约
- 句法Context的引入
考虑栈顶两个词 $\omega_0$ 和 $\omega_1$ ,及它们的在句法树里的最左最右两个修饰 $\omega_0l$,$\omega_0r$,$\omega_1l$,$\omega_1r$,文中考虑了2种一元特征和4种二元特征,最后得到的context如下
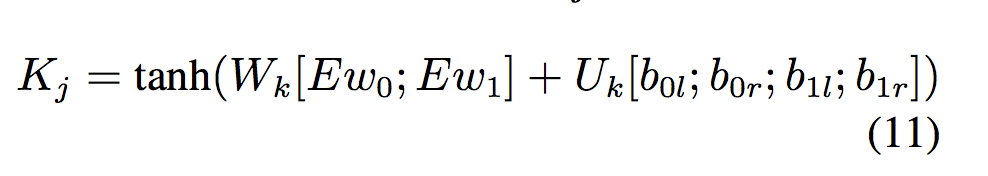
其中
注:Context只在model概率的时候用到,在计算hidden state时只利用了 $c_j$
- 训练和解码
训练目标为最大化
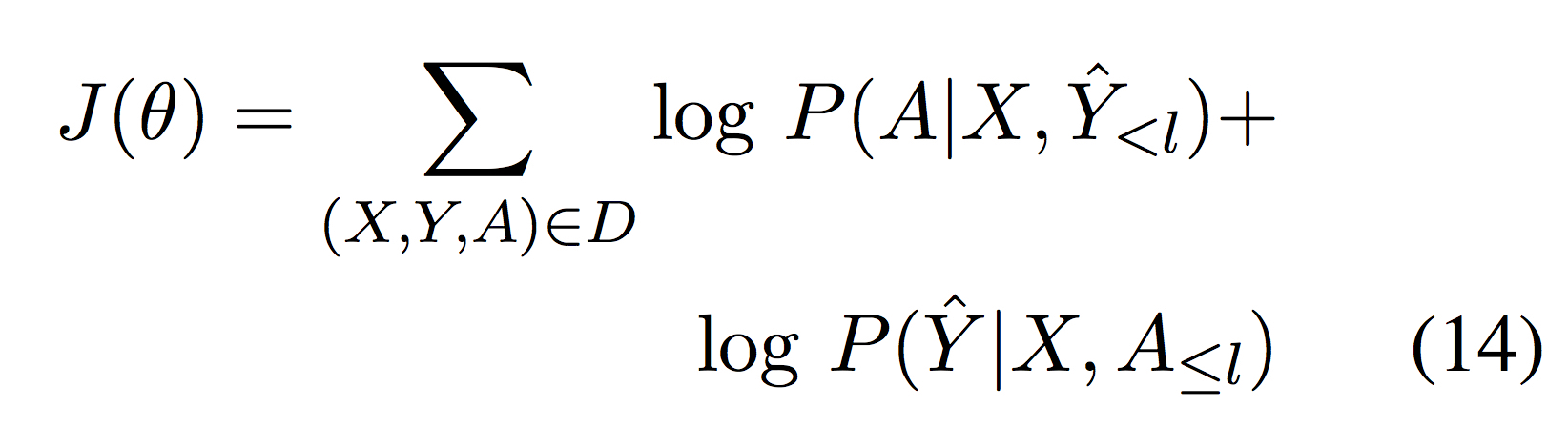
解码时score如下
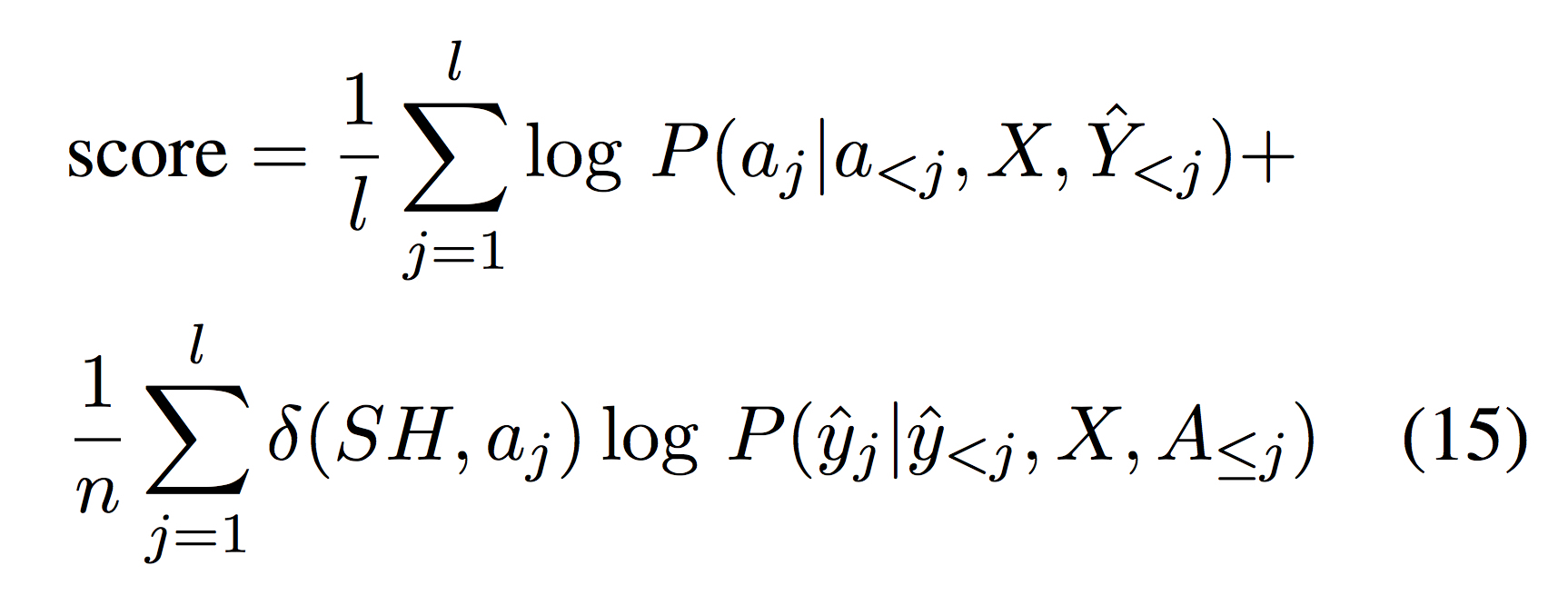
Experiments
Effect of dependency tree
直观上来说,action prediction时beam size越大,则dependency tree质量越高
作者通过调大该beam size,观测到翻译BLEU值的提升,从而说明建立dependency tree能够增强目标词生成