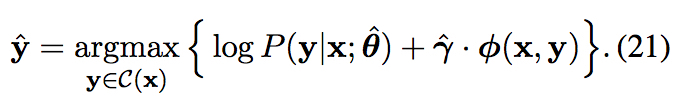Motivation
在NMT系统中,很难将先验知识整合到神经网络中去。
- 一方面,神经网络使用连续的实数值向量,很难从语言学角度解释网络里每一层
- 另一方面,先验知识一般以词典、规则等离散形式表示,不容易变成神经网络需要的连续形式
前人工作主要有修改模型架构和修改训练目标两种
但这些方法框架不能整合 multiple overlapping, arbitrary prior knowledge sources
神经网络通常会在隐藏状态之间强加独立的假设,这使得扩展神经网络架构需要显式地对不同信息源之间的相互依赖关系进行建模;而修改训练目标也只能局限在有限的几种简单限制上
Methods
Posterior Regularization
基本思想是通过 加入先验知识的分布 和 模型的后验分布之间的KL散度来约束模型
加入了后验正则化的似然函数为
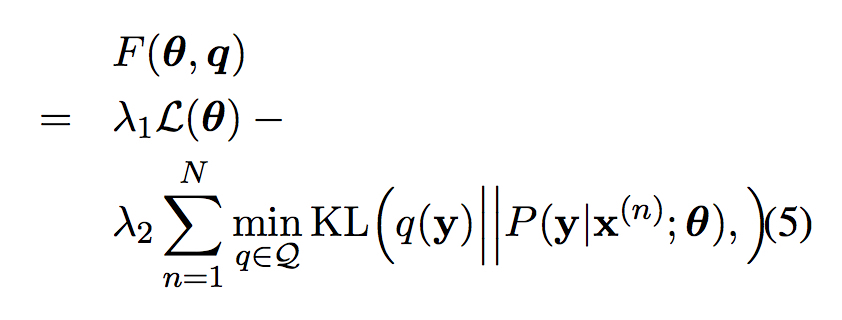
这里Q为约束后验的集合
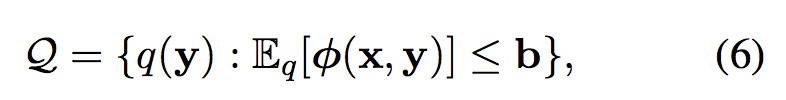
其中$\phi{(x,y)}$为约束特征,b是期望上界
使用EM算法来求解这个问题如下
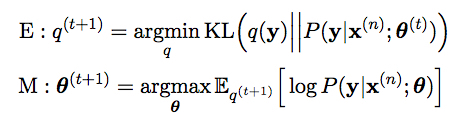
然而这个算法不能直接应用到NMT中,因为很难找到合适的界 b 来bound
Posterior Regularization for NMT

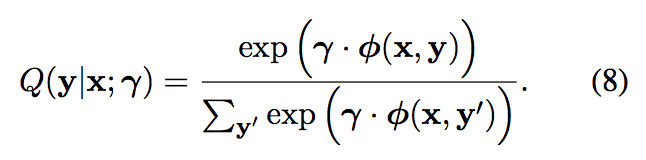
与上一节中介绍的方法主要区别为使用了 log-linear 模型来表示期望分布。
Feature Design
这一部分主要说明了如何为各种先验设计特征从而整合到模型中来,可以以后参考
Training
训练目标为最大化加入后验正则化的似然函数
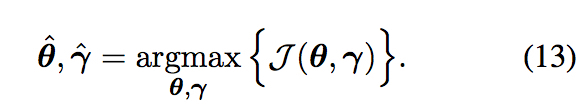
这里仍然有计算梯度时需要考虑所有候选翻译(指数级)的问题,因此同样采用从全部搜索空间中sample一个子空间来近似的方法,这一部分内容与MRT一文中一致
Searching
解码时同样可以加入先验知识,这里为了不影响方法的模型透明度,采用coarse-to-fine的方法,先用普通的score $P(\textbf{y}|\textbf{x};\mathbf{\hat{\theta}})$ 生成k个最好的候选翻译,然后使用下面的score加入先验知识选出最终翻译