Motivation
在NMT中加入 source 端语法树
Methods
同时在 encoder 和 decoder 中都加入 source 语法树信息
这里限制语法树为严格的二叉树
Tree-GRU Encoder
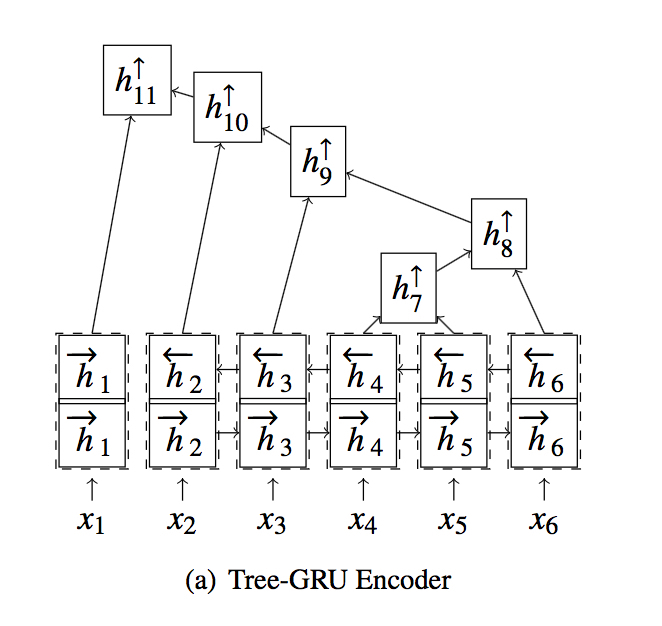
叶结点
直接使用 sequential encoder 的结果,即 $h_{k}^{\uparrow} = h_{k}^{\leftrightarrow}$
中间结点
使用左右儿子的函数结果, 即 $h_{k}^{\uparrow} = f(h_{L(k)}^{\uparrow}, h_{R(k)}^{\uparrow})$
这里的 $f(•)$ 原论文中是 Tree-LSTM,本文中改进为 Tree-GRU (文中有细节公式)
Bidirectional Tree Encoder
原来的 Tree Encoder 的问题在于自下而上,结点信息仅来自于下端而没有祖先结点传来的信息,尤其是对于叶结点即 words ,没有任何语法结构信息传入,因此提出自上而下的 Tree Encoder。
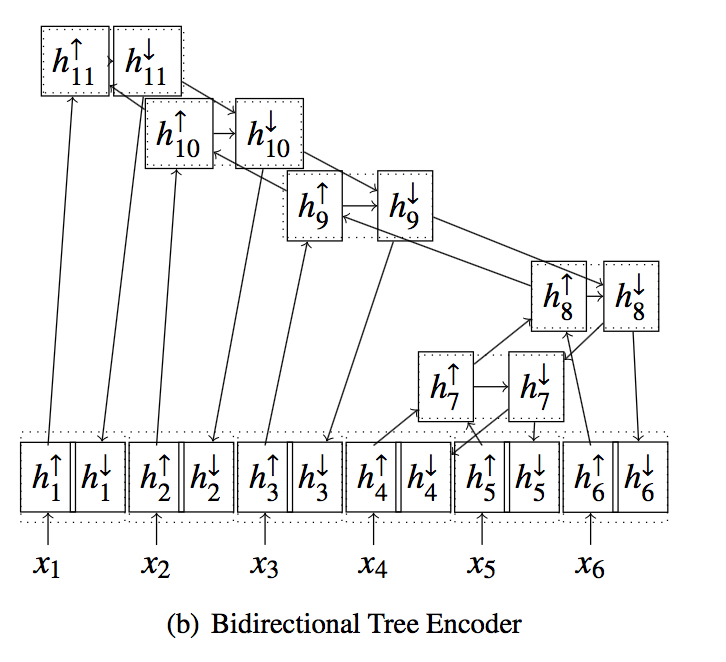
具体做法为先自下而上汇集信息到根结点,然后
初始化根结点向下信息如下
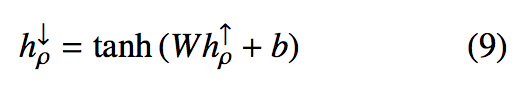
对每一个结点,计算其向下信息如下
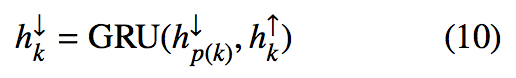
对每个结点,concat它的向上和向下信息,作为最后的表示
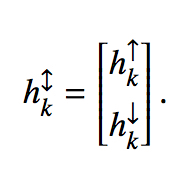
Tree-Coverage Model for Decoder
Word Coverage
对于 Word Coverage 信息,可以通过如下方法增强 attention 机制来加入:
计算 Coverage Vector
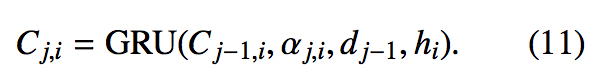
这里 $\alpha_{j,i}$ 是 attention weight,$d_{j-1}$ 是 Decoder 中的上一个隐状态,$h_i$ 是 encoder 端的编码信息
在 alignment 的计算加入对 Coverage Vector 的考量
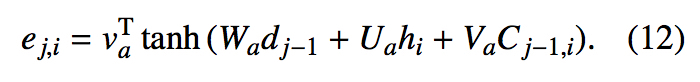
Tree-Coverage
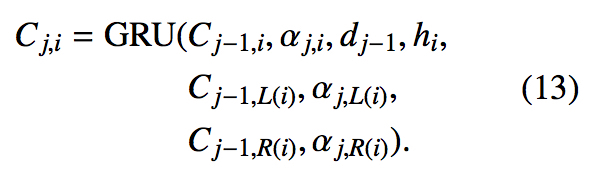
当一个子结点作出翻译时,父节点的 Coverage Vector 能够考虑到这一点,从而减少 over-translation 的问题
Questions
与另一篇 Model Source Syntax for NMT 的区别?
- 只用到 source 语法树的结构信息,没有用 label
- Encoder 整合语法树的方法不一样
- 在 Decoder 也考虑了语法信息
在 Tree-GRU 那张图中,为什么 h1 与后面的隐状态分开了?