Motivation
使用RNN作为encoder和decoder往往会有梯度爆炸/消失问题,优化困难。传统的做法是加residual或者fast-forward connections。本文提出使用Linear Associative Unit (LAU)来减少梯度传播的距离。
Method
GRU
GRU的激活函数由update门和reset门组成,隐状态计算如下:
其中
$\textbf{r}_{t}$ 是reset gate,$\textbf{z}_{t}$ 是update门
LAU
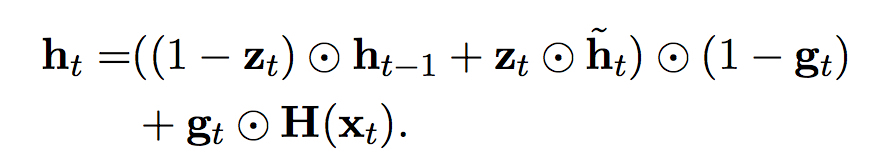
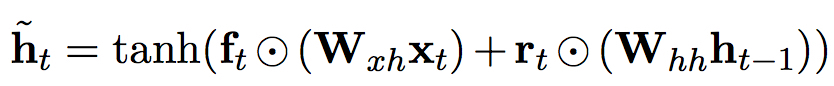
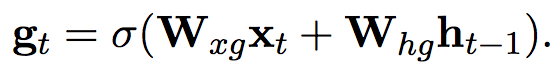
与普通的GRU相比,LAU增加了input门$g_{t}$,控制直接对应输入$x_{t}$的仿射变换量$H(x_{t}) = W_{x}x_{t}$
。这在翻译任务中有利于那些不应经过变换直接传递到下一个阶段的量,例如在翻译人名”Bahrain”时,LAU倾向于在隐层输出保持其embedding,而不是做出不必要的变换(由于有关”Bahrain”的训练数据较少)。
Experiments
SOTA of course.
架构基本上是替换LAU的RNN search.
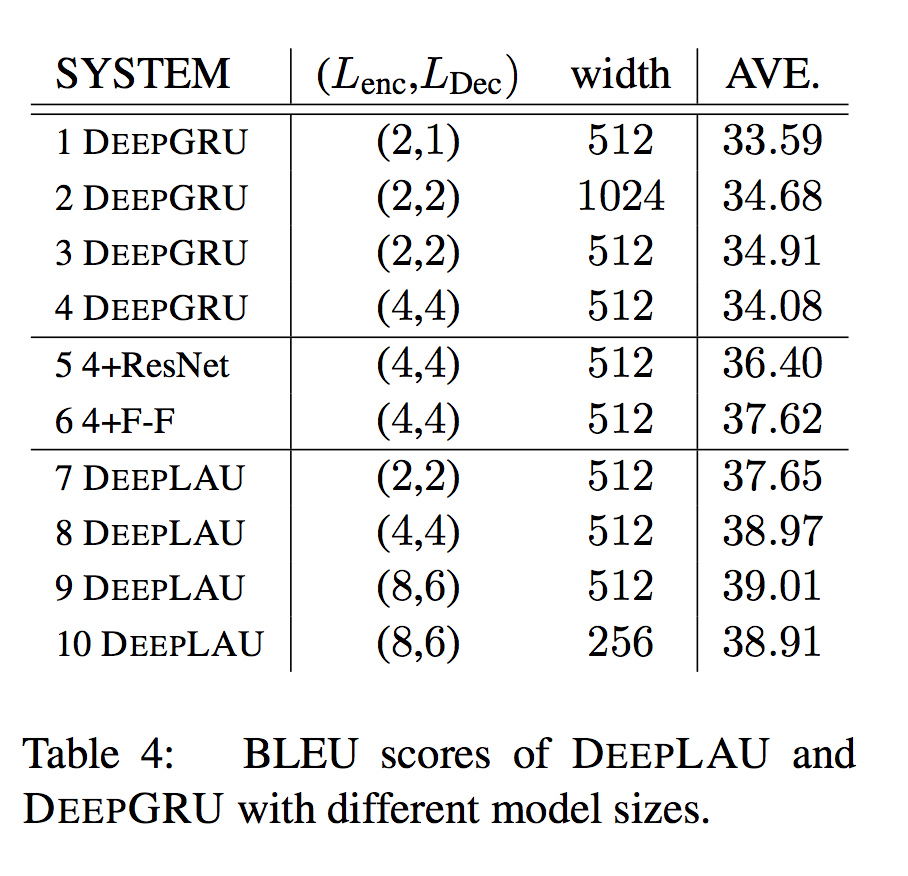
实验证明LAU能够支持更深层的RNN网络,取得更好的效果。
Questions
- POSUNK?
- 为什么这样设计?
- 为什么能够减少梯度衰减的情况?