Motivation
过去Chunk (Phrase)作为翻译中非常重要的概念,在现有NMT系统中并没有考虑
目前Decoder两个问题:
- long-distance dependencies
仅依赖记忆有限训练集上local word序列,来预测多种可能词序
例如日语中有时“早”和“家”两个字的顺序非常灵活,这使得仅仅记忆训练集上的词序并不好
在SMT中,chunks可以用来解决上述两个问题
本文扩展了现有RNN decoder,提出了三种模型来利用目标端词的chunk结构
本文将句子看成 句子->词组->单词 的三层结构
Methods
根本设计为将解码拆分成 chunk生成 和 word生成 两部分,使用两个decoder来分别model
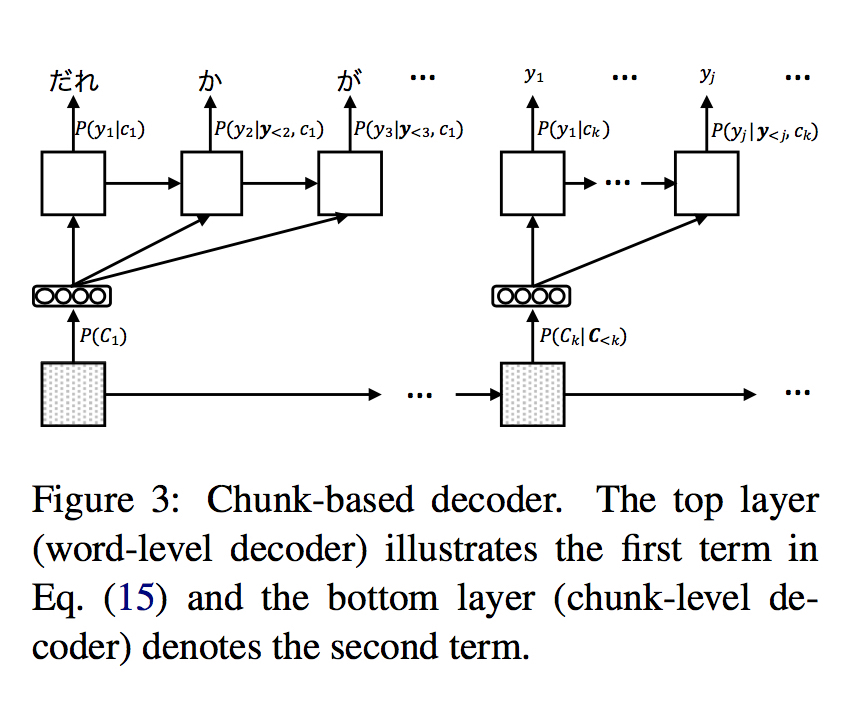
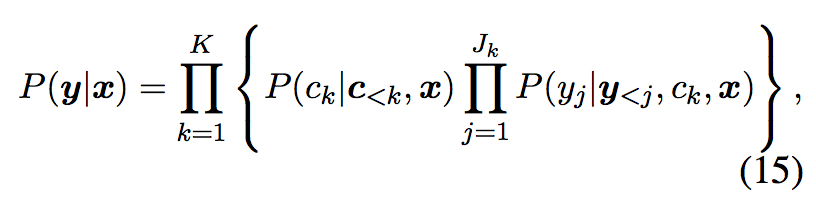
由于chunk为单位的序列显著较短,因此能缓解 long-distance 的问题
模型总体如下
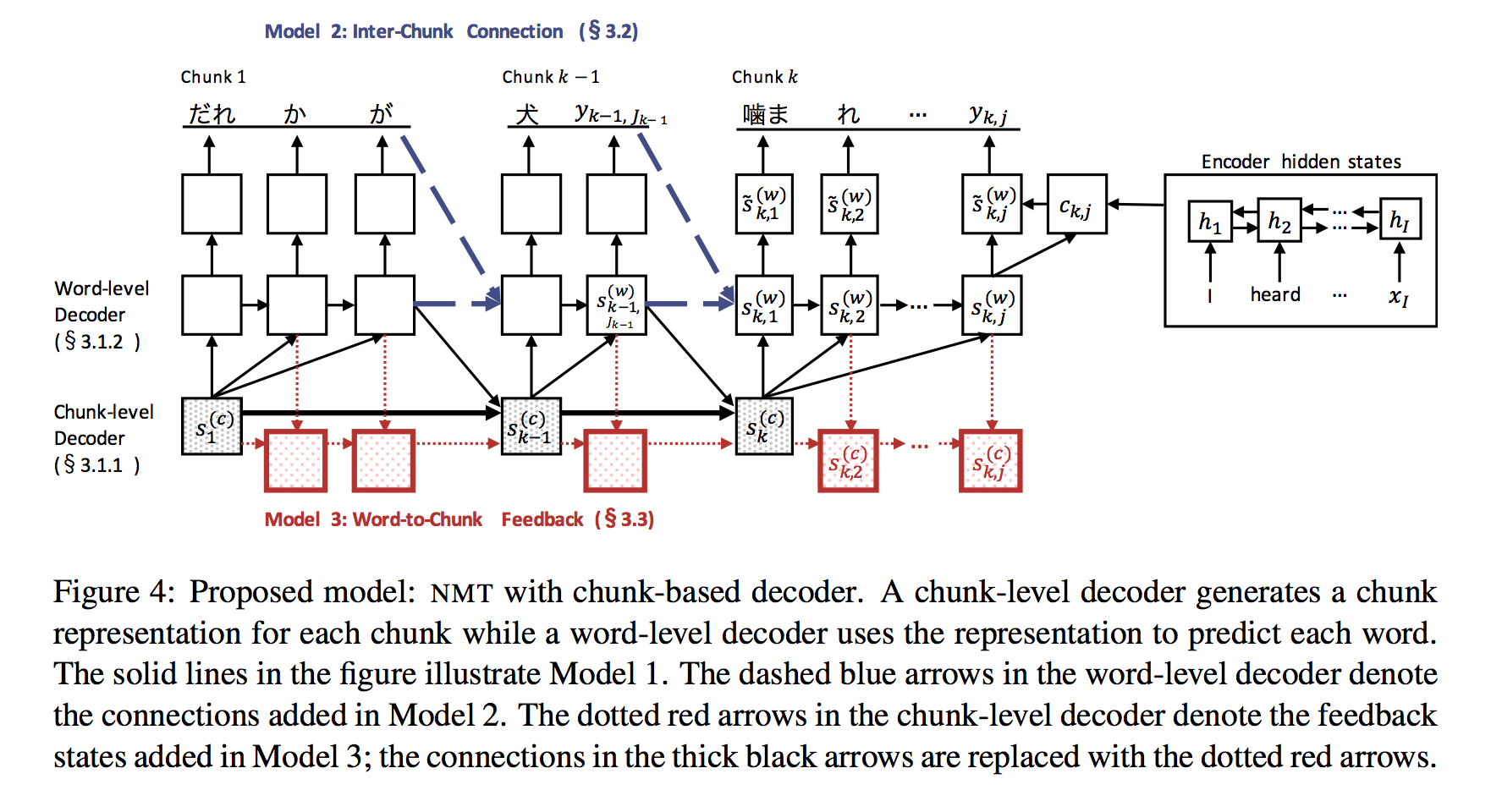
Basic Model (实线)
Chunk-level 接受两个输入
上一个Chunk隐层
word-level decoder的最后一个状态
Word-level 是普通decoder
Inter-Chunk Model (蓝虚线)
Basic Model中,每个chunk内部的 word-decoder 都是初始化,这会导致 word-level 的不连贯
加入上一个chunk最后一个状态和当前chunk第一个状态之间的连接以解决这个问题
Word-to-Chunk Feedback(红方框)
Chunk-level 受到 word-level 影响,添加图中红框的多个中间状态,以记忆已经产生的单词等信息,从而解决重复译、漏译等问题