Motivation
Problem description
端到端的NMT在某些特定语言或领域会存在数据匮乏问题。本文定义的任务为:
- 已有一个pivot-target的NMT系统(teacher),以及source-pivot的平行语料
- 求得一个source-target的NMT系统(student)
即解决zero-resource的NMT问题。
Current methods
针对无平行语料的翻译任务,主要有两种方法:
multilingual:
Multilingual的问题在于建模和训练时结合了多种语言,导致模型复杂度相比普通NMT增大
pivot-based:
pivot可以是文本或者图片。Pivot方法通常需要将解码分成两步,计算代价高,并且会有错误传播问题
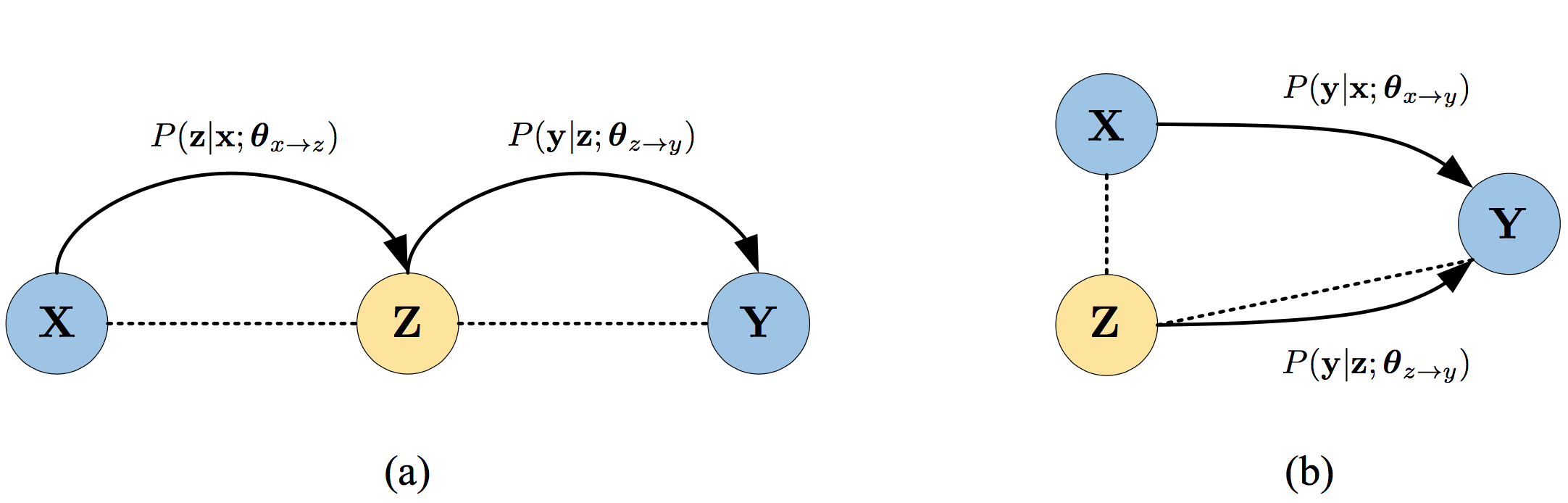
pivot-based对翻译架构透明,但第一步的错误会影响第二部分翻译。
因此需要探究直接从source到target的翻译模型。
Methods
本文基于的假设是:平行语句在生成第三种语言的一个句子时应该具有相近的概率。
这可以进一步归约到如下两个假设:
若source端语句$\textbf{x}$与pivot端语句$\textbf{z}$互为翻译,那么$\textbf{x}$和$\textbf{z}$翻译出target端语句$\textbf{y}$的概率应该接近
若source端语句$\textbf{x}$与pivot端语句$\textbf{z}$互为翻译,那么在已经获得了部分翻译$\textbf{y_{<j}}$时,$\textbf{x}$和$\textbf{z}$翻译出下一个词y的概率应该接近
Sentence-Level
针对第一种假设自然得到下面的训练目标
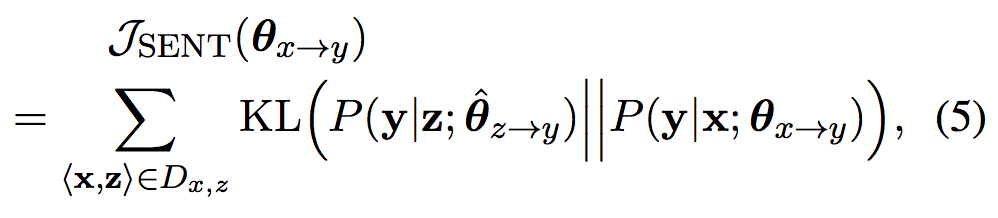
其中
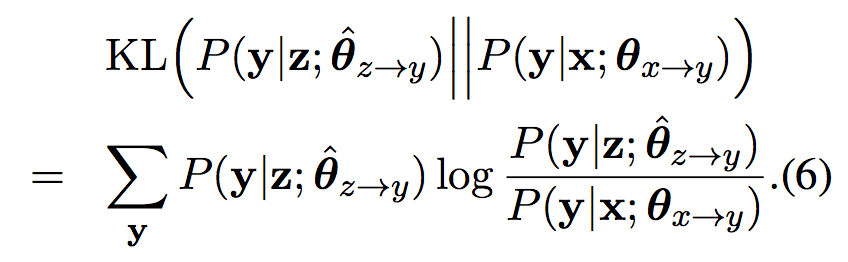
由于teacher模型$\textbf{z}\rightarrow{\textbf{y}}$是已有固定模型,训练目标可以化为
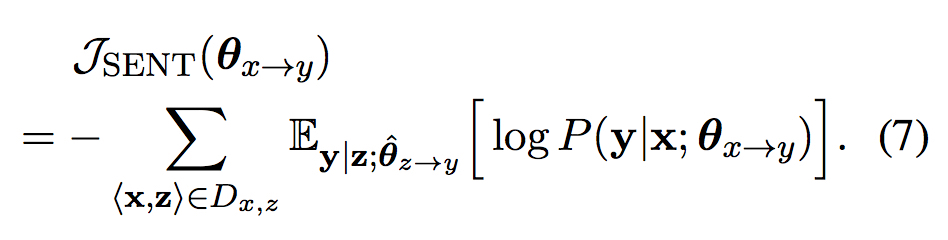
P.S. 这里的推导与负对数似然(NLL)训练目标的推导一致
由于$\textbf{y}$指数爆炸,训练比较困难。可以采用的策略有
- 采样
- 生成k-best list
- mode approximation(?)
Word-Level
针对第二种假设得到下面的训练目标
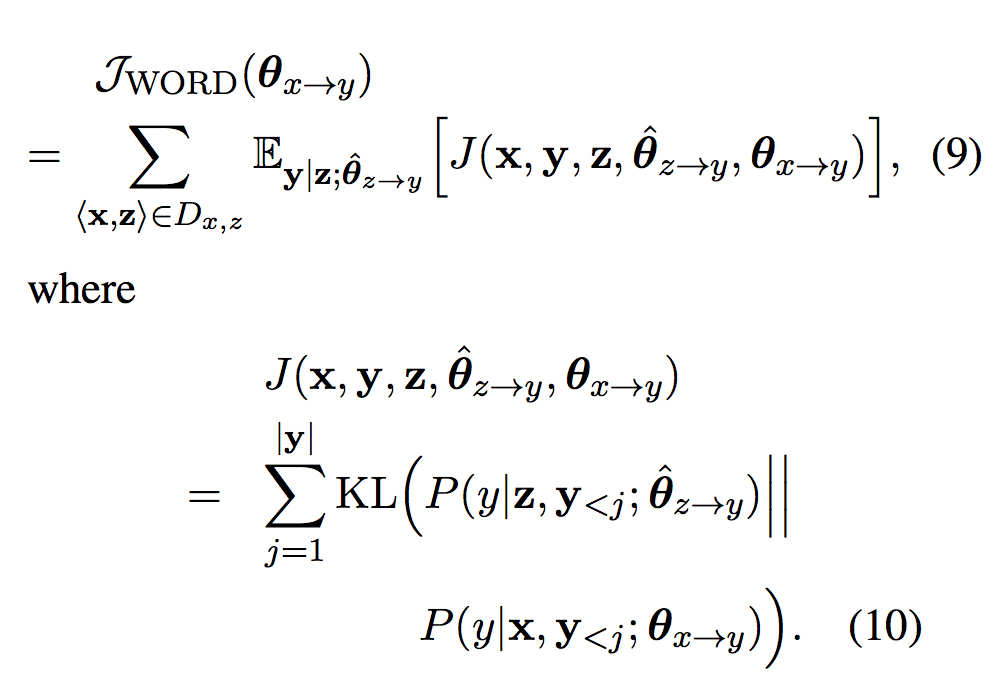
同Sentence-Level部分的推导,该训练目标等价于
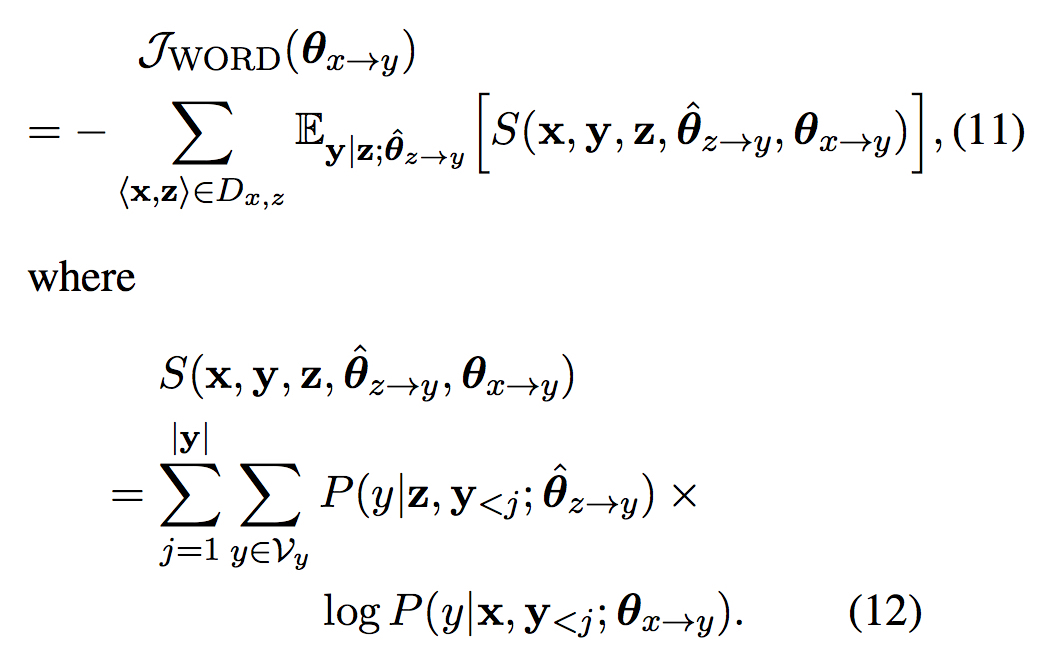
Experiments
- 验证实验
使用传统方法首先训练pivot-target模型并固定,之后训练source-target,观察两个训练目标的值,发现均有下降
- 常规实验
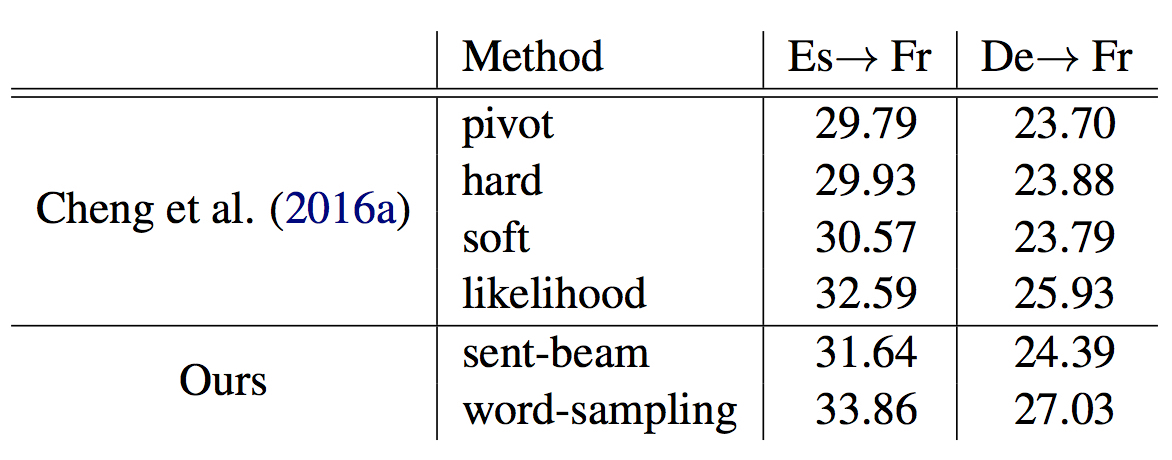
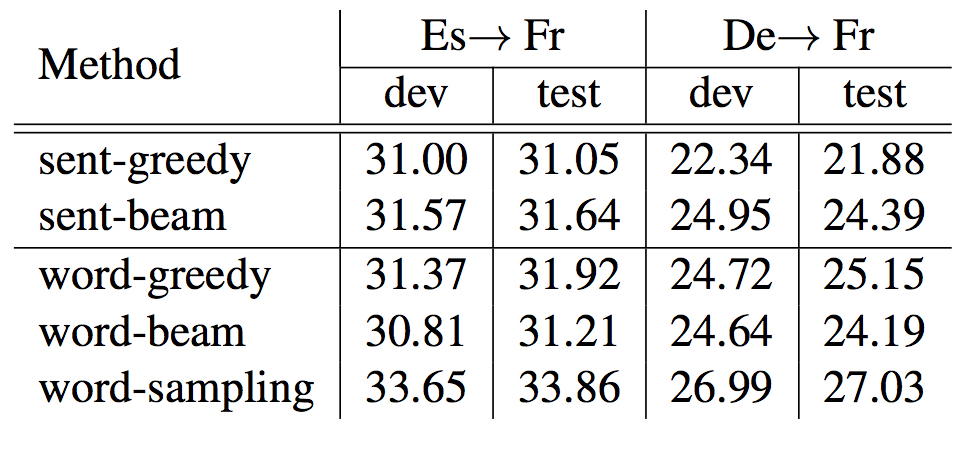
- source-pivot小数据实验
使用 word-sampling + 某篇论文中的initialization and parameter freezing strategy
Question
- mode approximation?
- initialization and parameter freezing strategy?
- 感觉文章很清楚明白,没什么其他想提的问题