Motivation
目前的 attention 机制建模能力有限,不能做到在解码时重新编码 source 。
本文提出了一种替代方法,该方法于跨两个序列的单个2D卷积神经网络。网络的每一层都根据当前的输出序列重新编码源令牌。因此,类似注意力的属性在整个网络中普遍存在。我们的模型在实验中表现出色,优于目前最先进的编码器-解码器系统,同时在概念上更简单,参数更少。
- CNN 和 RNN 的区别
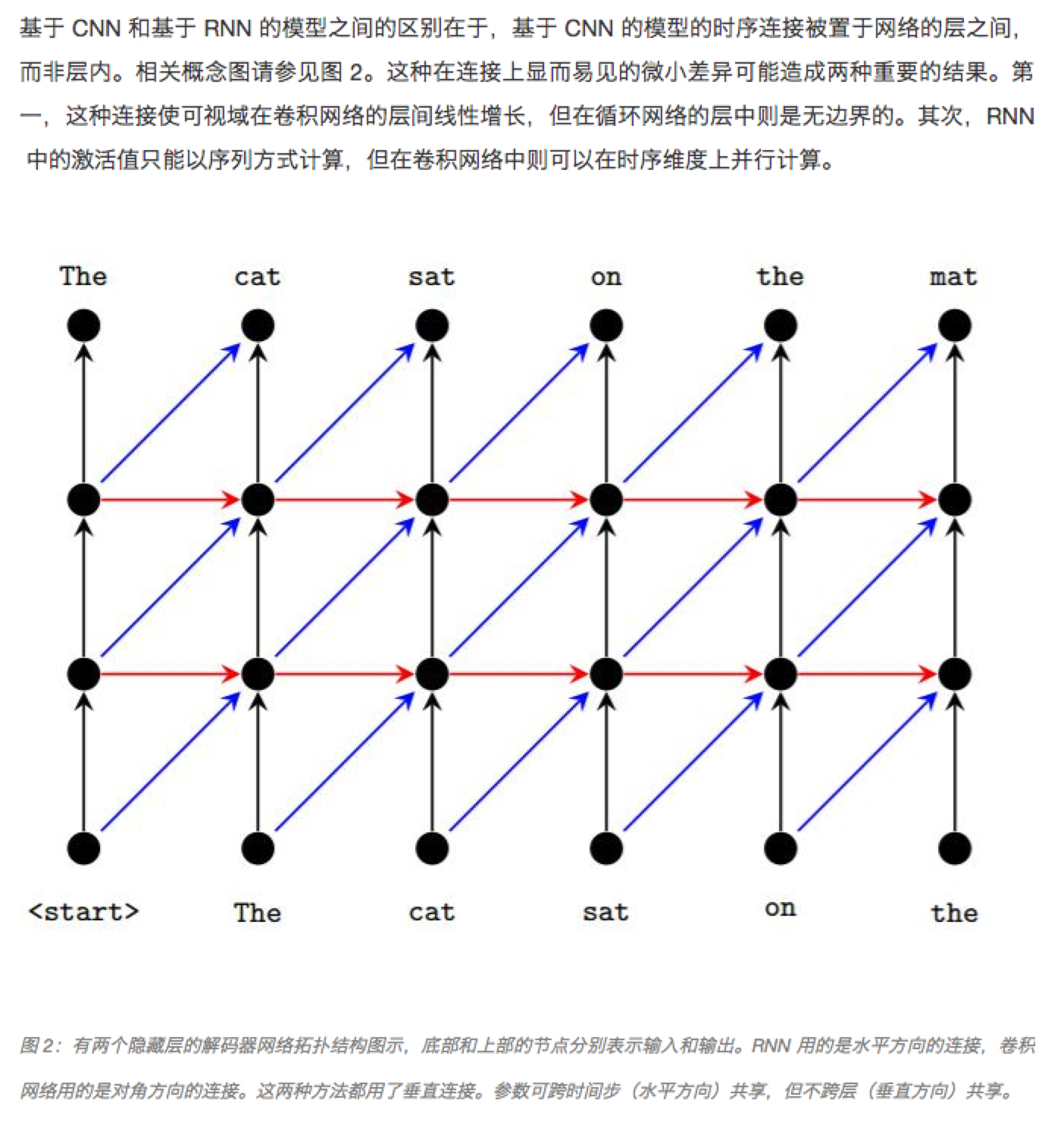
Methods
对输入序列和输出序列对 $(s, t)$ ,将它们连接起来构成一个 3D tensor $X \in{} R^{|t|\times{|s|}\times{f_{0}}}$ ,这里 $f_{0} = d_t + d_s$,并有
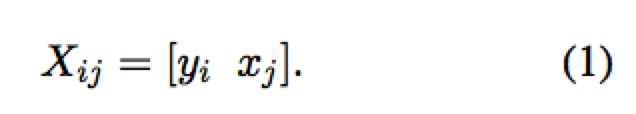
得到类似网格的结构如下
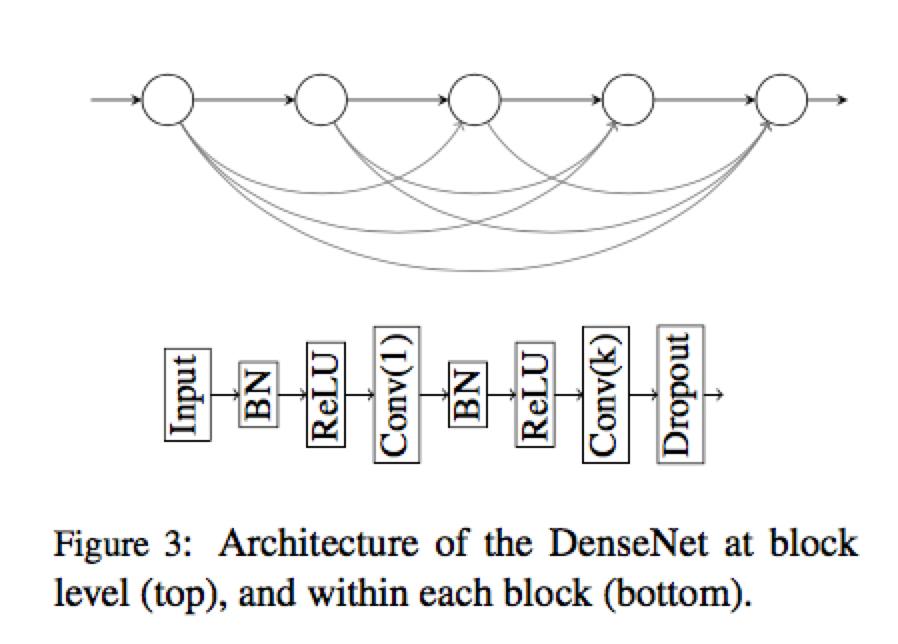
作者采用一个 masked Dense CNN 网络来直接建立 source 序列与 target 序列之间的 feature map ,如图中蓝色部分所示。这样可以保证特征由已知信息 (source 和已经产生的 target)得到。Dense的含义时每一层都与之前的每一层相连而不仅仅是上一层,具体结构如下所示
在经过如上图 L 层的 CNN 之后,我们可以得到 L 层 feature map,第 l 层的维度为 $|t|\times{|s|}\times{f_{l}}$
在作 target sequence prediction 时,我们需要采用 pooling 将这些特征中有关源序列的第二个维度 $|s|$ 消掉,这里可以采用 max-pooling 或 average-pooling
- max-pooling
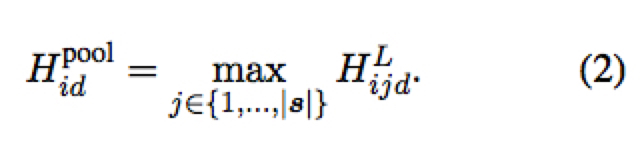
- average-pooling
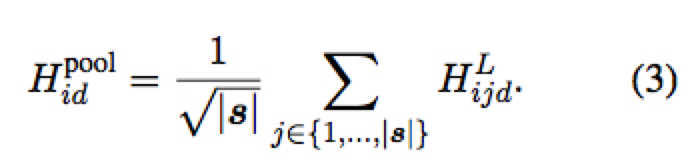
之后通过 $|V|\times{f_L}$ 的投影矩阵 E 得到有关预测词的概率分布
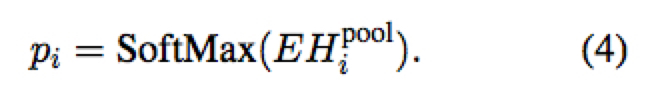
这里 E 也可以映射到 $d_t$ ,然后通过乘以 $|V|\times{d_t}$ 的 target embedding 矩阵来得到输出概率分布,这样做可以减少参数并提升效果。
之后可以通过类似 attention 机制计算第 i 个输出位置和第 j 个输入 token 之间的对齐度
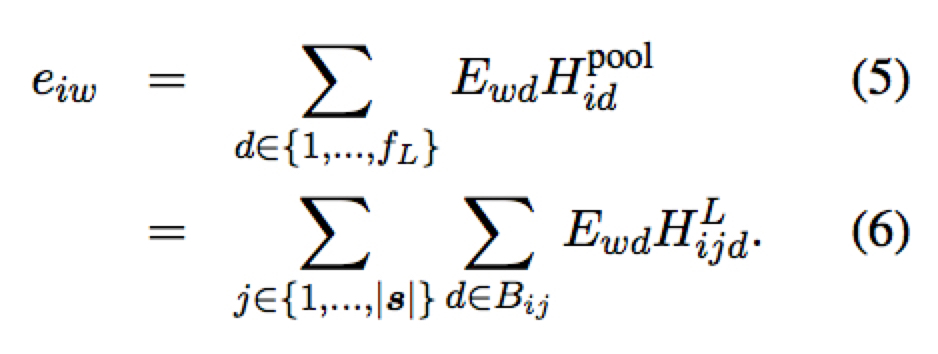
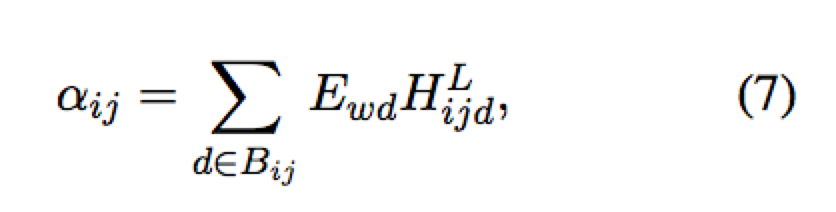
作者还考虑了通过 self-attention 计算出来的矩阵来代替或辅助 pooling 矩阵
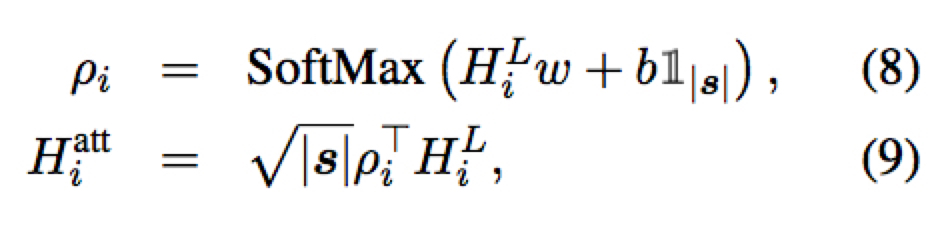
这里 $\rho_i$ 为 $|s|$ 维向量
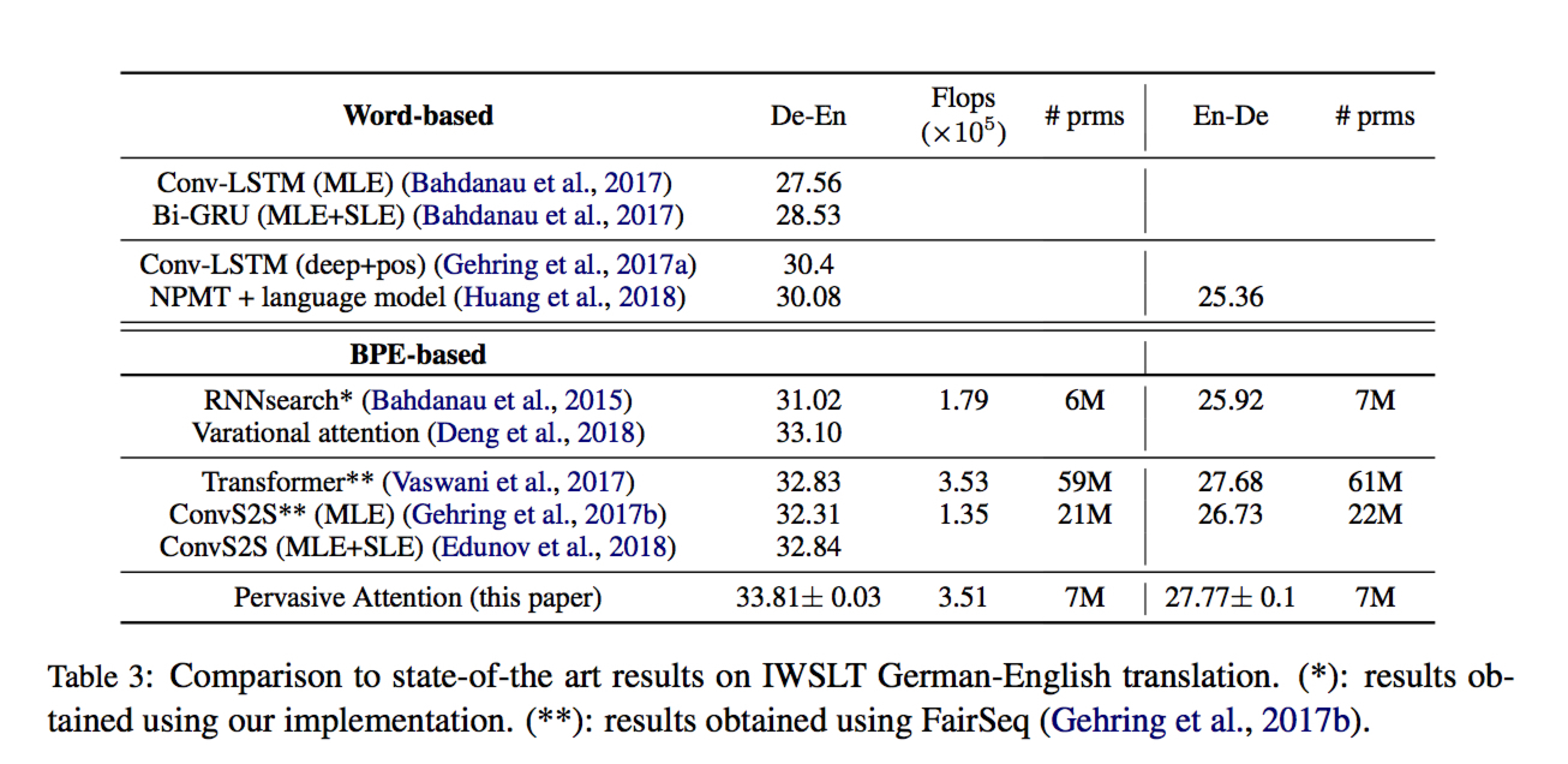
Experiments
与其他模型比较
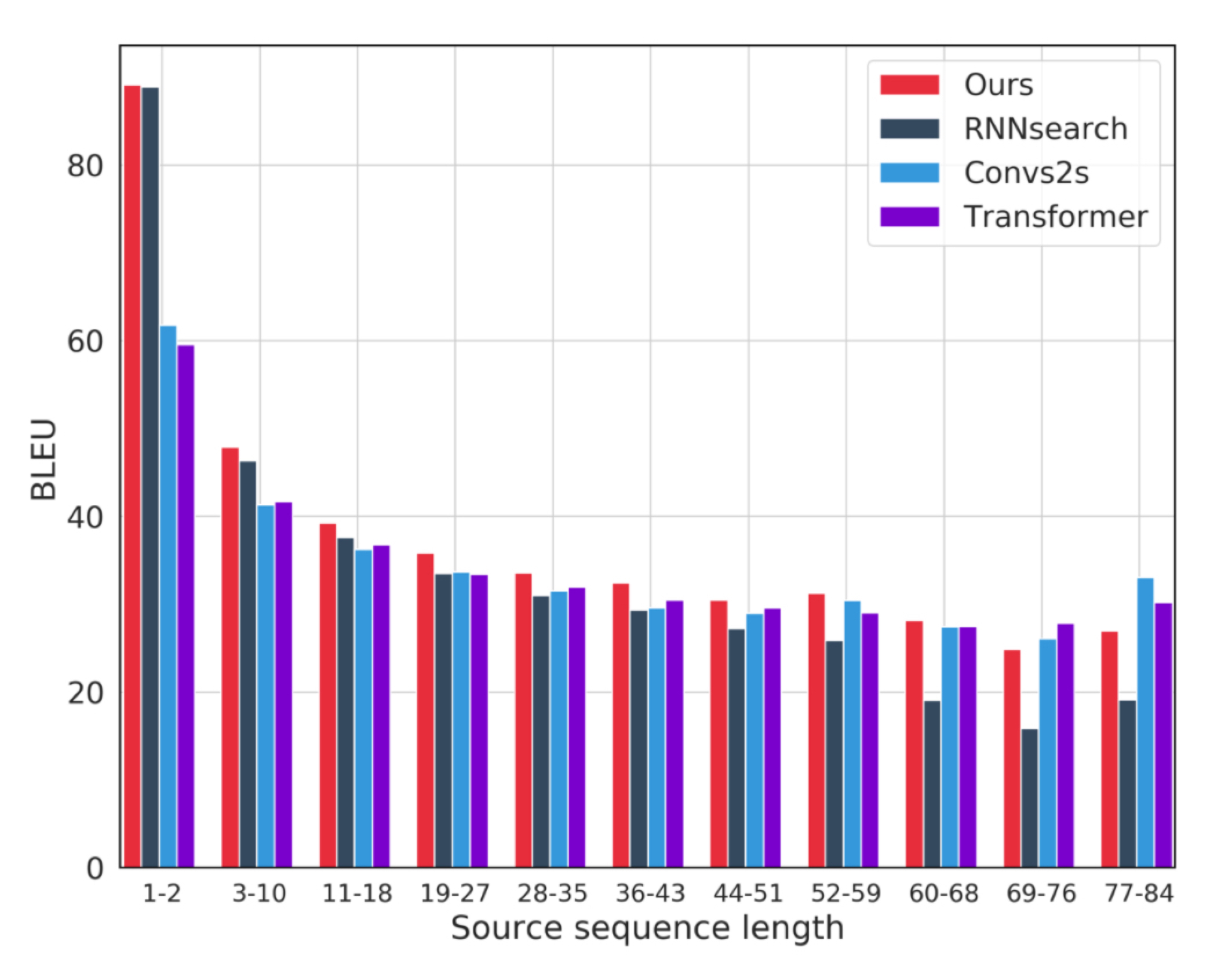
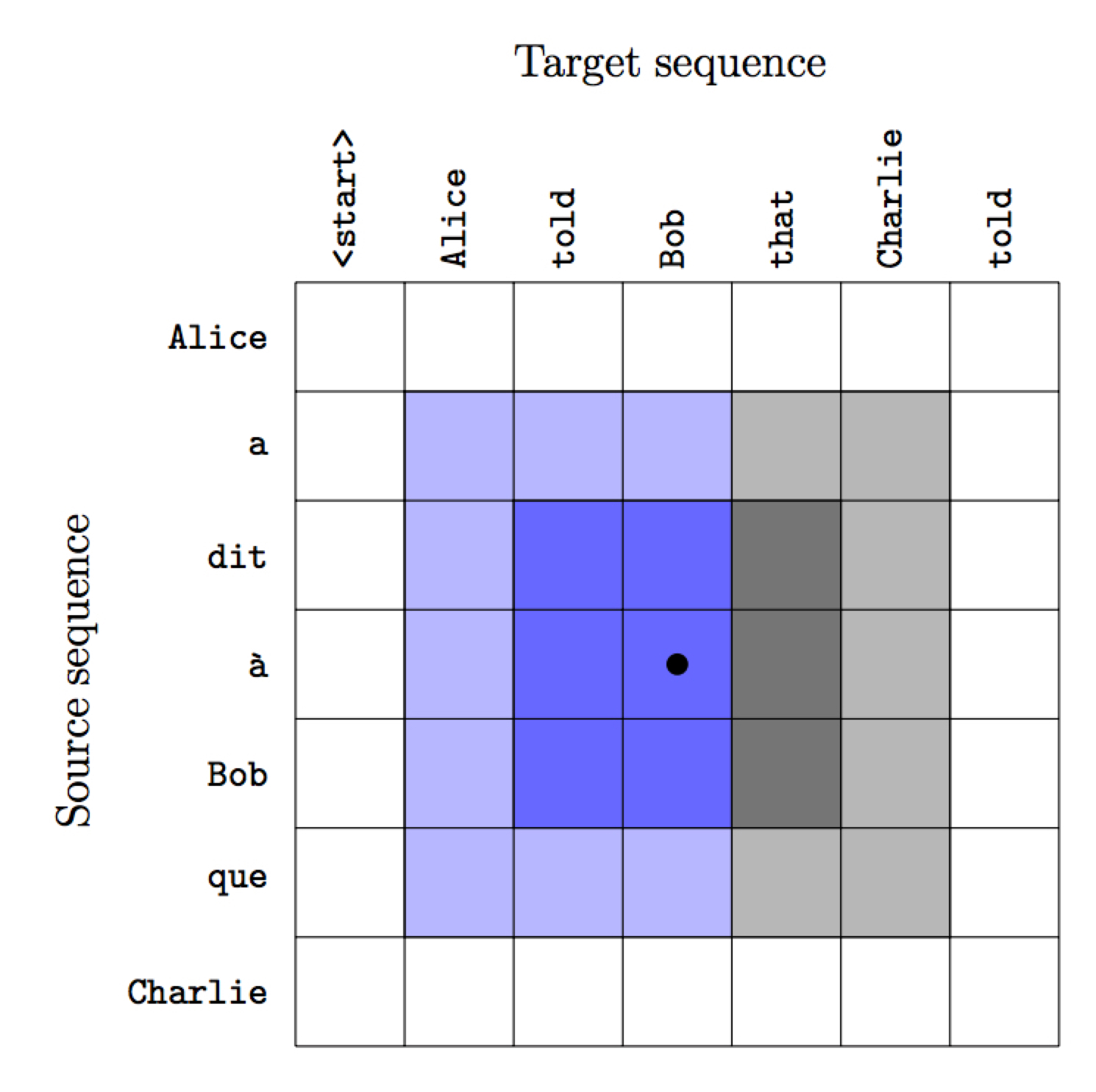
可视化 Implicit sentence alignment
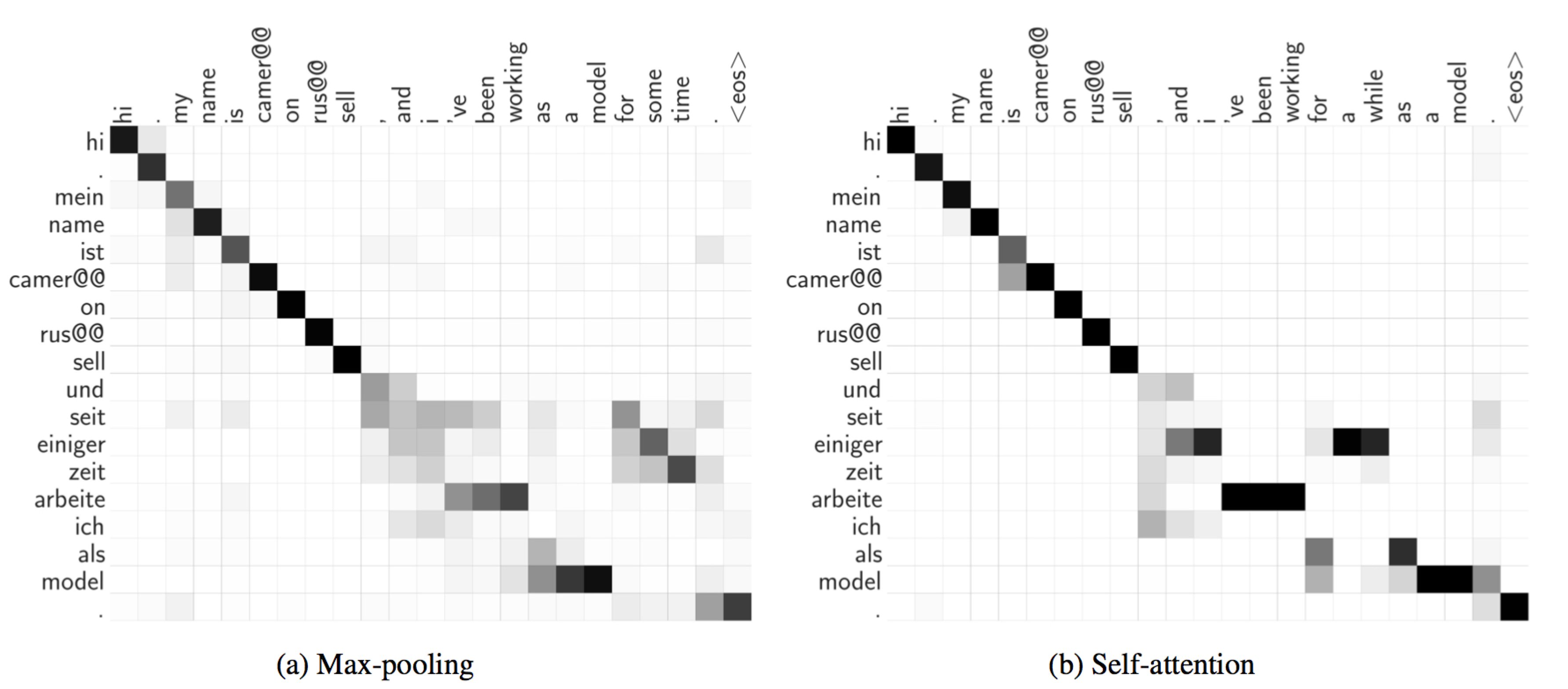
两边分别画出的是 $\alpha_{ij}$ 和 $\rho_i$